BEPRO Dev Team
How Python Severless Services Operate at BEPRO
How do we benefit from being able to develop using a serverless platform?

Most of BEPRO’s backend services are written in Python. A Main API service is one of them. The service is currently operating in a serverless architecture and we are deploying it through Zappa, a serverless open source management tool.
In this article, I would like to briefly introduce how Python serverless services operate at BEPRO.
What is Serverless?
Before we talk about serverless at BEPRO, I think it would be good to take a brief look at serverless itself. First, let us take a look at what the “Big Three” cloud vendors are saying about serverless.
Build and run applications without thinking about servers
AWS provide several serverless services. (Lambda, API Gateway, Aurora Serverless etc.)
Develop and deploy highly scalable applications and functions on a fully managed serverless platform.
They also provide some serverless services.(Cloud Run, Cloud Functions etc.)
The serverless name comes from the fact that the tasks associated with infrastructure provisioning and management are invisible to the developer.
Finally, Martin Fowler’s blog (martinfowler.com), one of my favourite technical blogs, also talks about serverless.
Serverless had become a dominant name for this area, giving way to the birth of the Serverless Conference series, and various Serverless vendors embracing the term in everything from product marketing to job descriptions.
As a result, it would be good to think of serverless as an “environment where developers can develop without having to worry about infrastructure”, through serverless services provided by cloud vendors such as the “Big Three” discussed above. In addition, the above martinfowler.com article explains in detail the concept, pros and cons of serverless, so if you are interested, I strongly recommend that you read it before moving on.
Why did BEPRO adopt Serverless?
Why did BEPRO adopt a serverless environment?
Limited Development Resources
One of the most important reasons is the situation at BEPRO where we had to utilise limited resources as efficiently as possible at the beginning of the business. We needed an environment in which a few developers could develop and operate our products without considering infrastructures as much as possible, rather than hiring new DevOps developers, because we were not sure how quickly our service would grow at the time.
API Traffic Patterns

This is a typical API call pattern (measured every second) for three hours on a weekend. The server handles 10 to 20 times the normal request for a very short time. This is very irregular(depending on match schedules). In normal situations, relatively few infrastructure resources are sufficient to handle this traffic, but resources must be scaled out or up for a short time in order to guarantee the same performance at peak times. These traffic patterns are very irregular depending on weekends/weekdays and seasonal/nonseasonal periods.
In this situation, we need to either maintain infrastructure resources which can handle peak traffic, or configure an auto-scaling environment. In the former case, cost is wasted, and in the latter case, it might be scaled up or out too late, because the traffic has already decreased as resources are scaled up or out. As mentioned above, our resources (especially developers) were quite limited when it came to manage infrastructure, considering these factors.
In a serverless environment, developers do not have to worry about these traffic patterns, since cloud vendors that provide serverless services manage their infrastructure on their own. By taking a serverless approach we thought our developers could concentrate on developing business logic and features. We could also launch our new features at speed thanks to serverless.
Cost
In addition to the system operation perspective, we roughly compared the estimated cost of an AWS serverless environment and a traditional server environment. (Specific costs such as RDS, Load Balancer, and S3 are not considered for approximate estimation purposes only.)
Assumptions: 2,000,000 requests / month
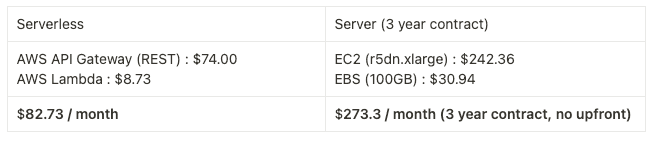
We can see that the AWS serverless environment is about 70% cheaper.
Bepro adopted a serverless environment, despite some disadvantages such as limited number of concurrent executions, limited execution time, cold start delay, etc. (See general pros and cons of serverless.)
Serverless Architecture at Bepro
We decided to use AWS serverless services. BEPRO’s architecture is shown in brief below. (Details such as CDN, S3, etc. are omitted to show a serverless environment only.)
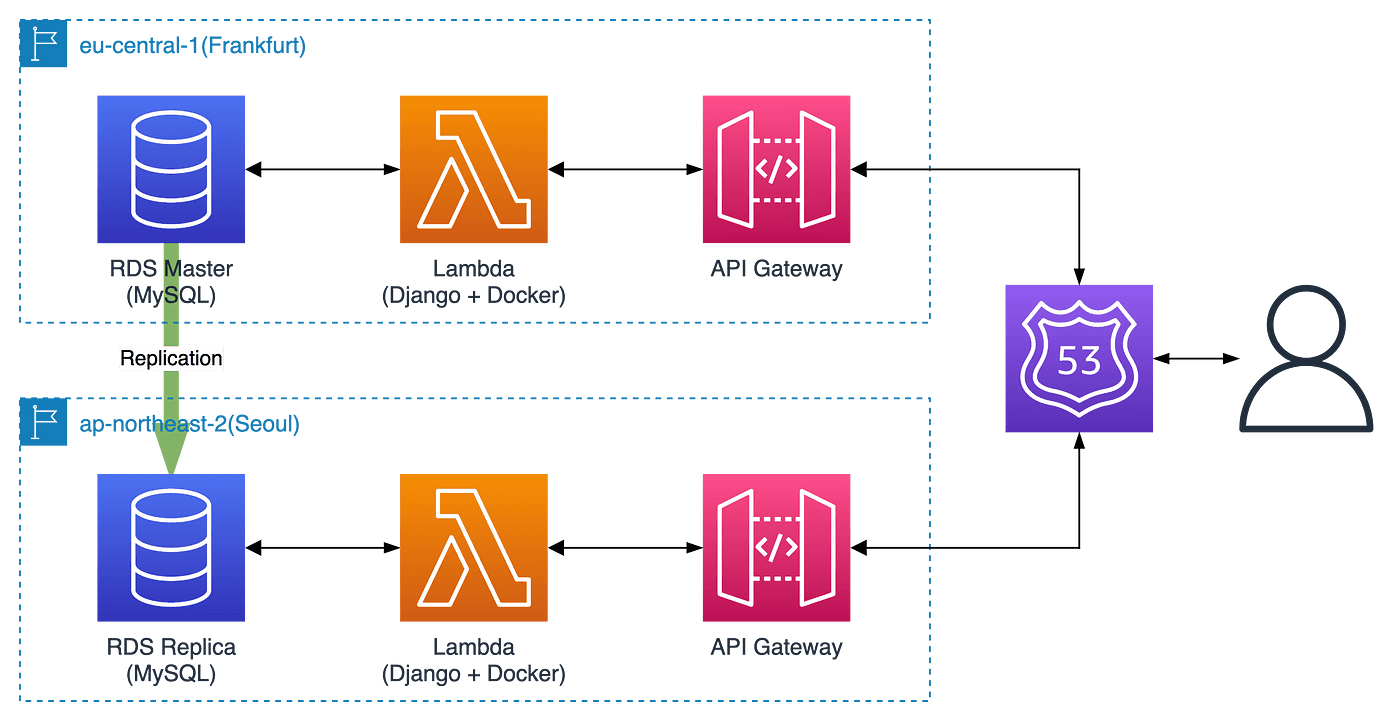
We tried to optimise our API response latency by configuring Europe and Asia as multiple regions to provide global services. We also deployed a Lambda environment using Docker containers. All of this serverless management is done by Zappa, an open source tool.
Deploying Python Web Services with Zappa
Now, we are going to deploy Python web services with Zappa.
If you deploy web services to AWS serverless without Zappa, you will have a headache because there are so many things to consider, such as IAM Role, code packaging, API Gateway/Lambda settings, etc. — Zappa handles all of this automatically.
Let us see how to deploy a Docker based serverless Python Django web service with Zappa.
Django Project Settings
First, create a Python virtual environment and install Django.
(venv)> pip install django
Create a Django project.
(venv)> django-admin startproject zappa-example
(venv)> cd zappa-example
ALLOWED_HOSTS in Django settings has been modified. Also, we’ve commented out database related settings to run this example smoothly.
... (skip) ...
ALLOWED_HOSTS = ["*"]
... (skip) ...
# DATABASES = {
# 'default': {
# 'ENGINE': 'django.db.backends.sqlite3',
# 'NAME': 'mydatabase',
# }
# }... (skip) ...
Run a Django server on your local environment.
(venv) python manage.py runserver
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced).
You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.
Run 'python manage.py migrate' to apply them.
June 14, 2022 - 15:09:23
Django version 4.0.5, using settings 'zappa_example.settings'
Starting development server at <http://127.0.0.1:8000/>
Quit the server with CONTROL-C.
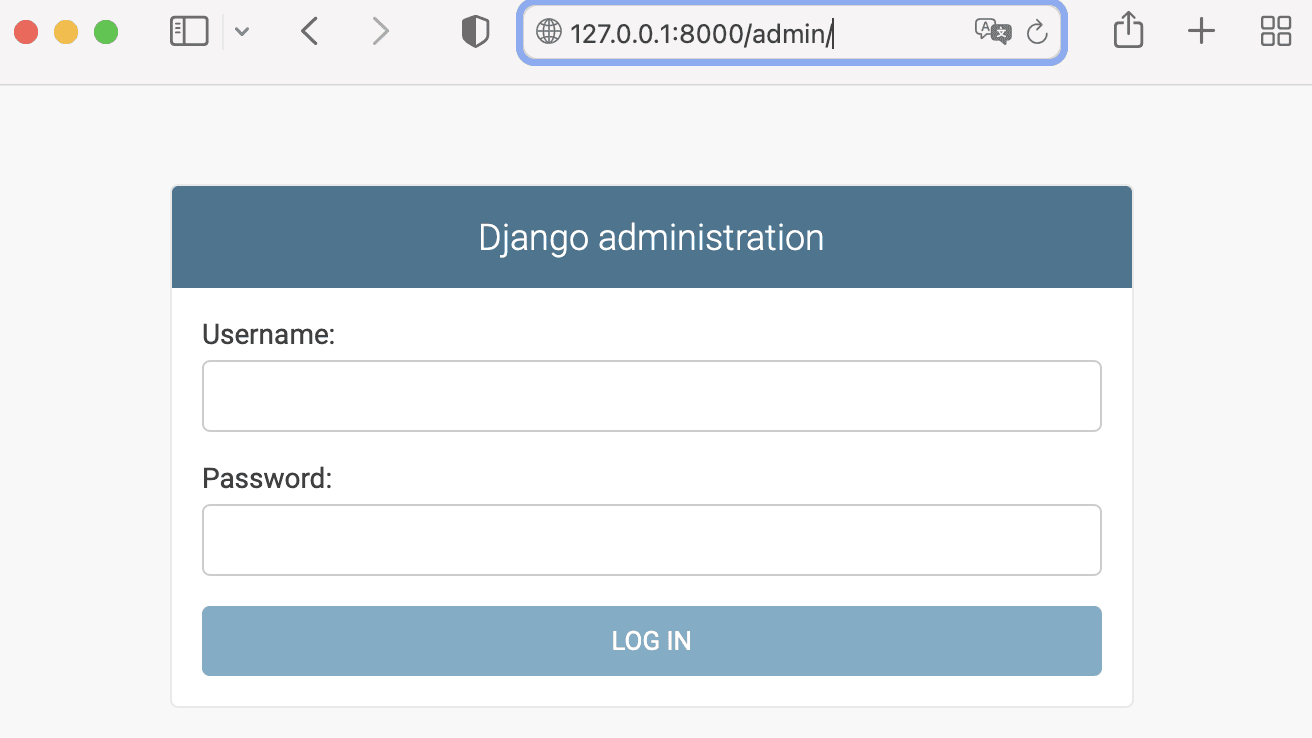
We can connect to the local Django server through your browser. (In this example, we will not implement any functions, but simply test by accessing the Django admin login page.)
Zappa Settings
We need to set our AWS credentials prior to completing our Zappa settings
First, install awscli.
> pip install awscli
Set AWS credentials using aws configure command.
> aws configure
Install the Zappa library on your Python virtual environment that you created above.
(venv)> pip install zappa
Before initialising Zappa, create a requirements.txt file to specify dependencies. (It will be used for deploying with Docker later.)
(venv)> pip freeze >> requirments.txt
Initialise Zappa.
(venv)> zappa init
We will go into the interactive mode for Zappa settings. I proceeded with the default values. A thing to note in the middle of the conversation is that Zappa recognised that our directory is a Django project and set it up automatically.

Enter “ls” command.
(venv)> ls
db.sqlite3 manage.py zappa_example
zappa_settings.json
A file zappa_settings.json has been created. Let us see the contents of that file.
{
"dev": {
"aws_region": "ap-northeast-2",
"django_settings": "zappa_example.settings",
"profile_name": "default",
"project_name": "zappa-example",
"runtime": "python3.8",
"s3_bucket": "zappa-yyamukhwg"
}
}
A stage dev has been created. (Default.) You can create multiple stages (staging, production, etc.) and each can be deployed.
aws_region : AWS region to be deployed.
django_settings : If it is Django project, specify the Django settings file path.
profile_name : AWS CLI configuration profile.
project_name : project name for Lambda function.
runtime : Runtime environment for Lambda (not required for deploying with Docker image).
s3_bucket : The s3 bucket to upload the deployment package (zip file) to.
Zappa deployment is super easy.
(venv)> zappa deploy dev
... (skip) ...
Deployment complete!: <https://7qi7rn36uf.execute-api.ap-northeast-2.amazonaws.com/dev>
Compress the code into a zip file, upload it to the S3 bucket, create Lambda function, set API Gateway, etc. — Zappa handles multiple deployment processes with only one command.
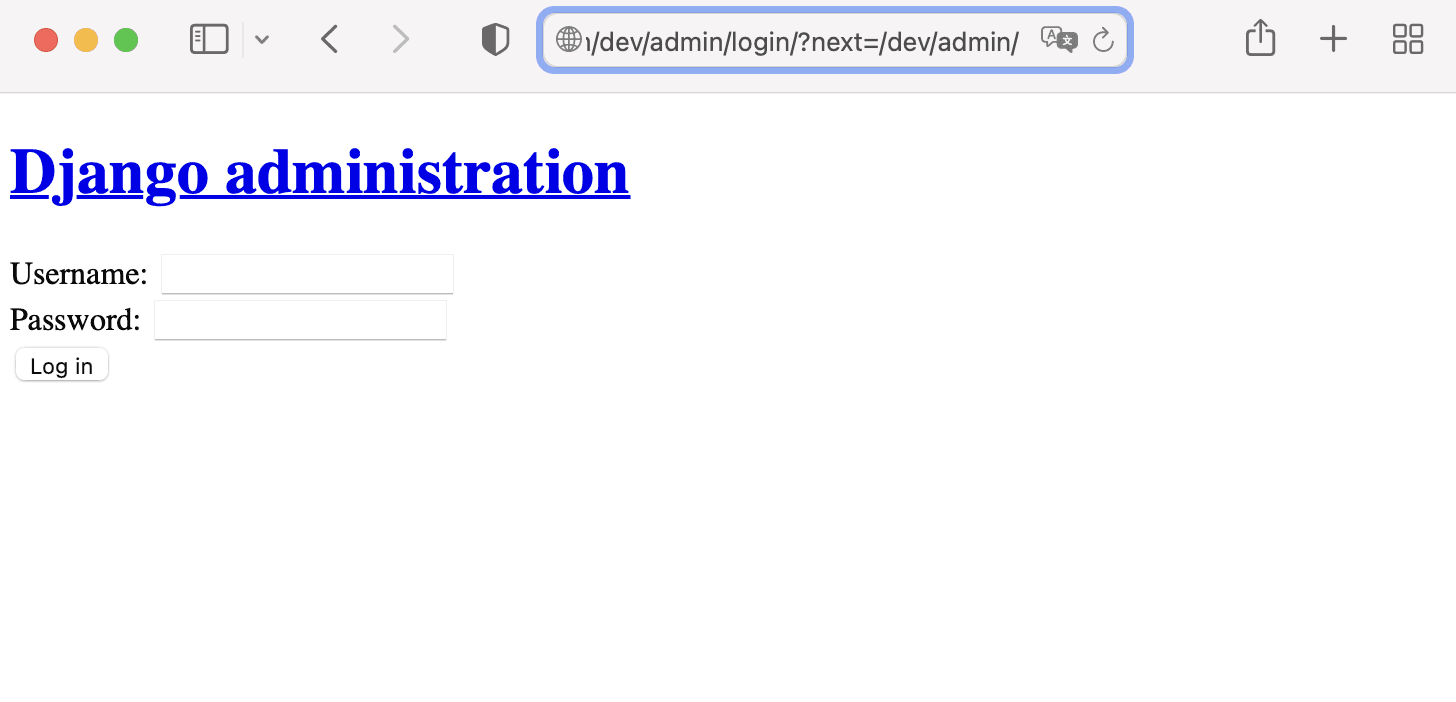
We can check the admin page can be accessed by using the last output url. (Style is not applied because static files are not deployed.)
We can remove our deployed application completely.
(venv)> zappa undeploy
Next, we are going to deploy with a Docker image.
Building a Docker Image
Create a Dockerfile.
FROM amazon/aws-lambda-python:3.8 # 1
ARG FUNCTION_DIR="/var/task/"
WORKDIR ${FUNCTION_DIR}
COPY ./ ${FUNCTION_DIR}
# Install packages
RUN pip install -r requirements.txt
# Grab the zappa handler.py and put it in the working directory
RUN ZAPPA_HANDLER_PATH=$( \\
python -c "from zappa import handler; print (handler.__file__)"
\\
) \\
&& echo $ZAPPA_HANDLER_PATH \\
&& cp $ZAPPA_HANDLER_PATH ${FUNCTION_DIR}
CMD [ "handler.lambda_handler" ] # 2
#1 : We used a Lambda based image provide by AWS(See)
#2 : Run a lambda handler provided by Zappa. (It will handle API Gateway requests and route them to the Django server.)
Create a settings file for Docker deployment before building an image.
(venv)> zappa save-python-settings-file dev
zappa save-python-settings-file <stage_name> format
In general, with zip file based Zappa deployment, a python setting file is packaged into the zip file. The same file (zappa_settings.py) is created and will be included in the Docker image.
Now build an image.
> docker build -t zappa-example:latest .
Pushing a Docker Image
Create an AWS ECR Repository.
> aws ecr create-repository --repository-name zappa-example --image-scanning-configuration scanOnPush=true
Retag.
> docker tag zappa-example:latest XXXXXXXXXXXX.dkr.ecr.ap-northeast-2.amazonaws.com/zappa-example:latest
Log in to the AWS ECR you created above.
> aws ecr get-login-password | docker login --username AWS --password-stdin XXXXXXXXXXXX.dkr.ecr.ap-northeast-2.amazonaws.com/zappa-example
Push the image to the ECR.
> docker push XXXXXXXXXXXX.dkr.ecr.ap-northeast-2.amazonaws.com/zappa-example:latest
Deploying with a Docker Image
Finally, deploying a Serverless Web Service with Docker image to AWS serverless.
(venv)> zappa deploy dev -d XXXXXXXXXXXX.dkr.ecr.ap-northeast-2.amazonaws.com/zappa-example:latest
... (skip) ...
Deployment complete!: <https://g9vu4sutk2.execute-api.ap-northeast-2.amazonaws.com/dev>
Check if the deployment is successful by accessing the output URL.
If you have already deployed your application, then you are required to update your latest application code on AWS by using the following commands.
(venv)> zappa save-python-settings-file dev
> docker build -t XXXXXXXXXXXX.dkr.ecr.ap-northeast-
2.amazonaws.com/zappa-example:latest .
> docker push XXXXXXXXXXXX.dkr.ecr.ap-northeast-
2.amazonaws.com/zappa-example:latest
(venv)> zappa update dev -d XXXXXXXXXXXX.dkr.ecr.ap-northeast-
2.amazonaws.com/zappa-example:latest
Use zappa update rather than zappa deploy
Custom Domain with SSL
We will use AWS Route 53 for domain and AWS Certificate Manager for SSl certificate.
I assume that Domain and Certificate have been issued completely.
First, modify zappa_settings.json, adding domain and certificate_arn value.
{
"dev": {
"aws_region": "ap-northeast-2",
"django_settings": "zappa_example.settings",
"profile_name": "default",
"project_name": "zappa-example",
"s3_bucket": "zappa-yyamukhwg",
**"domain": "zappa.cwoojin.com",**
**"certificate_arn": "arn:aws:acm:us-east-
1:XXXXXXXXXXXX:certificate/eba3fd6b-a1f4-4e6a-b5d6-fe7aa8c88649"**
}
}
Finally, just deploy!
(venv)> zappa certify
(venv)> zappa update dev -d XXXXXXXXXXXX.dkr.ecr.ap-northeast-
2.amazonaws.com/zappa-example:latest
..(skip)...
Your updated Zappa deployment is live!: <https://zappa.cwoojin.com> (<https://g9vu4sutk2.execute-api.ap-northeast-2.amazonaws.com/dev>)
Check if the connection to the registered domain is successful. (https://zappa.cwoojin.com.)
The basic deployment setup is now complete.
(Do not forget to undeploy this example from your AWS.)
Zappa Settings at BEPRP
I share some parts of the zappa_settings.json that we use at BEPRO.
BEPRO operates a deployment environment divided into multiple stages (dev, test, prod, etc.)
Please see a Zappa official document for advanced Zappa usage.
{
"dev": {
"aws_region": "eu-central-1",
"django_settings": "xxx",
"project_name": "xxx",
"s3_bucket": "xxx",
"environment_variables": {
...
},
"certificate_arn": "xxx",
"domain": "xxx",
"route53_enabled": false, "cors": {
"allowed_headers": [xxx]
},
"exception_handler": "xxx",
"keep_warm_expression": "xxx",
"memory_size": xxx,
"payload_compression": xxx,
"payload_minimum_compression_size": xxx,
"lambda_description": "xxx",
"vpc_config": {
"SubnetIds": [xxx],
"SecurityGroupIds": [xxx]
}
},
"prod_base": {
... (skip) ...
},
"prod": {
"extends": "prod_base",
"events": [{
"function": "task_1",
"expression": "cron(0/2 * * * ? *)"
}, {
"function": "task_2",
"expression": "cron(* * * * ? *)"
},]
... (skip) ...
},
"prod_asia": {
... (skip) ...
},
"test": {
"extends": "dev",
... (skip) ...
},
... (skip) ...
}
Conclusions
In this article, I briefly explained what serverless means, why BEPRO adopted serverless, and how to deploy python serverless web services with Zappa.
Zappa supports various features as well as the serverless deployment feature explained in this article. For example, it provides features like making it easy to invoke a Lambda function directly from application logic to run asynchronous tasks, or registering schedulers to run regular tasks as Lambda functions.
We finally built a serverless deployment environment using Github Actions and Zappa. The environment allowed our developers to focus more on business logic. Even now, there are still problems that need to be solved to improve the serverless environment and we are constantly thinking about solving these problems.
Finally, if you are thinking about building a Python Serverless Web Services, I hope this article was helpful.
Thank you!